
Based on the ever lasting questions who we are and what defines us, this project reflects different aspects of our identity in the twenty-first century.
The series, which should be viewed as a triptych, functions as abstract data visualization and represents one kind of identity within one poster.


genetic/left:
My biological identity is represented by raw genetic data from the chromosome X. Considering the average human has twenty-three chromosomes from one parent, which totals in 3.1 billion characters of genetic code or 3.1 GB of uncompressed data (respectively the double amount from both parents), the chromosome X still contains 158 million characters (A, C, G or T).
According to genetic research, some parts are directly responsible for generating proteins or controlling functions in our body. Other parts are repeated sequences, thus serve some kind of backup purpose and maintain secondary functions. Now each of these characters sets one pixel in a big image. The more important ones are colored in orange hues, while the repeated sequences are colored in blue tones – giving some impression for importance/redundance within the dataset.
computer/right:
Digital identity is represented by various technical data of my computer. Compared to the genetic and thus biological identity from a genome, the computer itself has naturally a lot of data which serves as a kind of its identity. More specifically these are all kind of different log files, system profiles, hardware informations, preferences and diagnostic reports. By choosing the right files, a comparable amount of plaintext information was collected to mimic the size of the chromosome X. Since those computer files contain more than four different characters, another algorithm was used: letters are human-readable and therefore contain important informations which we are able to understand primary, so these characters are colored by different orange pixels, while machine specific characters and numbers produce blue pixels. Again seperating them visually by importance.
personal/center:
Finally, in the center of the triptych and therefore between the biological and digital information level my personal data is located. Namely, these are all my calendar entries, contacts, mail messages, chat and browser histories, facebook, twitter and google archives from the last ten years. The amount of data is also comparable to both other sources, again containing mostly plain text information with numbers and machine specific characters.
There are many aspects to consider for interpretation. Starting by the fact, that our biological identity is digitally readable and storeable in the meantime, which seems quite ironic for the term biological. As well as the fact, that the human genome in general can be treated as a file is pretty interesting. Following that thought, the computer can therefore have some sort of identity as well. Between this transition from biological to digital data lies our identity. A human being interacting with the digital world produces different kind of data and patterns as the computer does. The transition is visually noticeable when the somehow organic structures from the genetic visualization is compared directly with the computer visualization, also considering the personal data right in between. But these are only some thoughts, as with visual and especially abstract art, any other interpretation is very welcome.

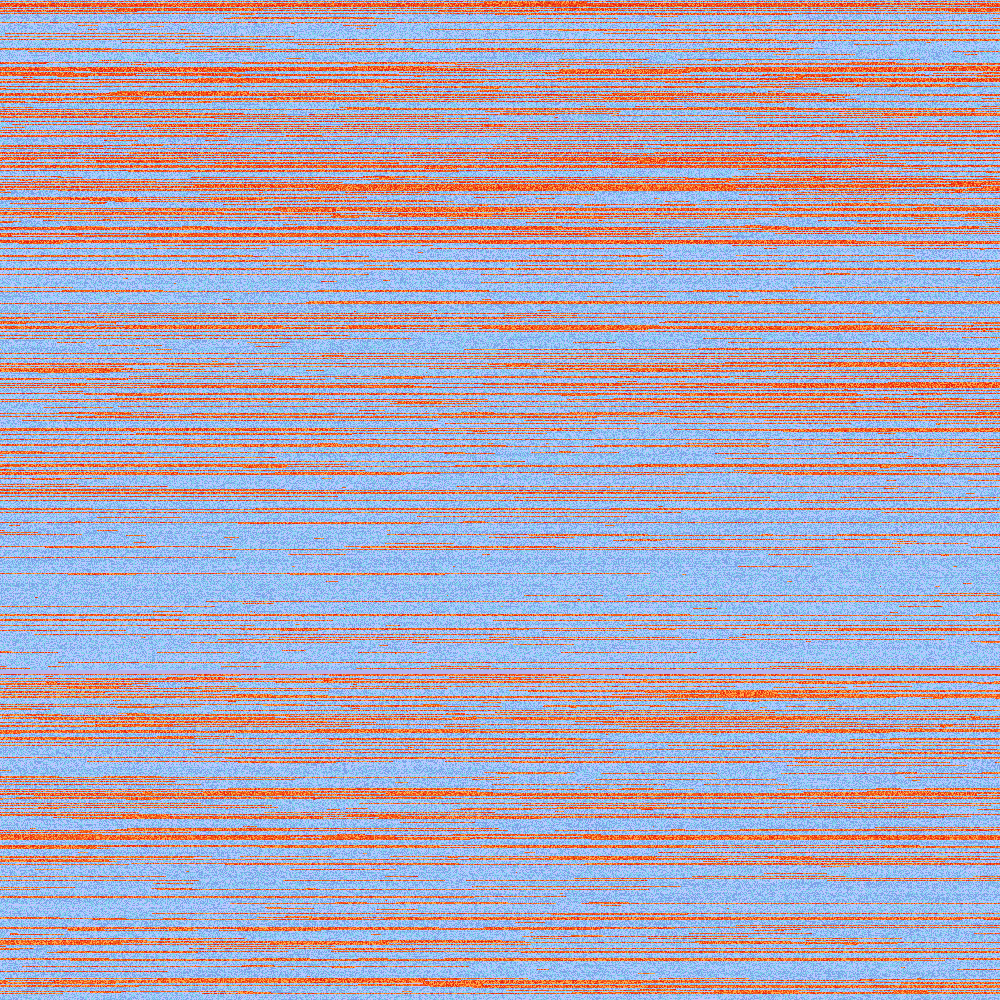
zoom into chromosome X


zoom into personal digital data
